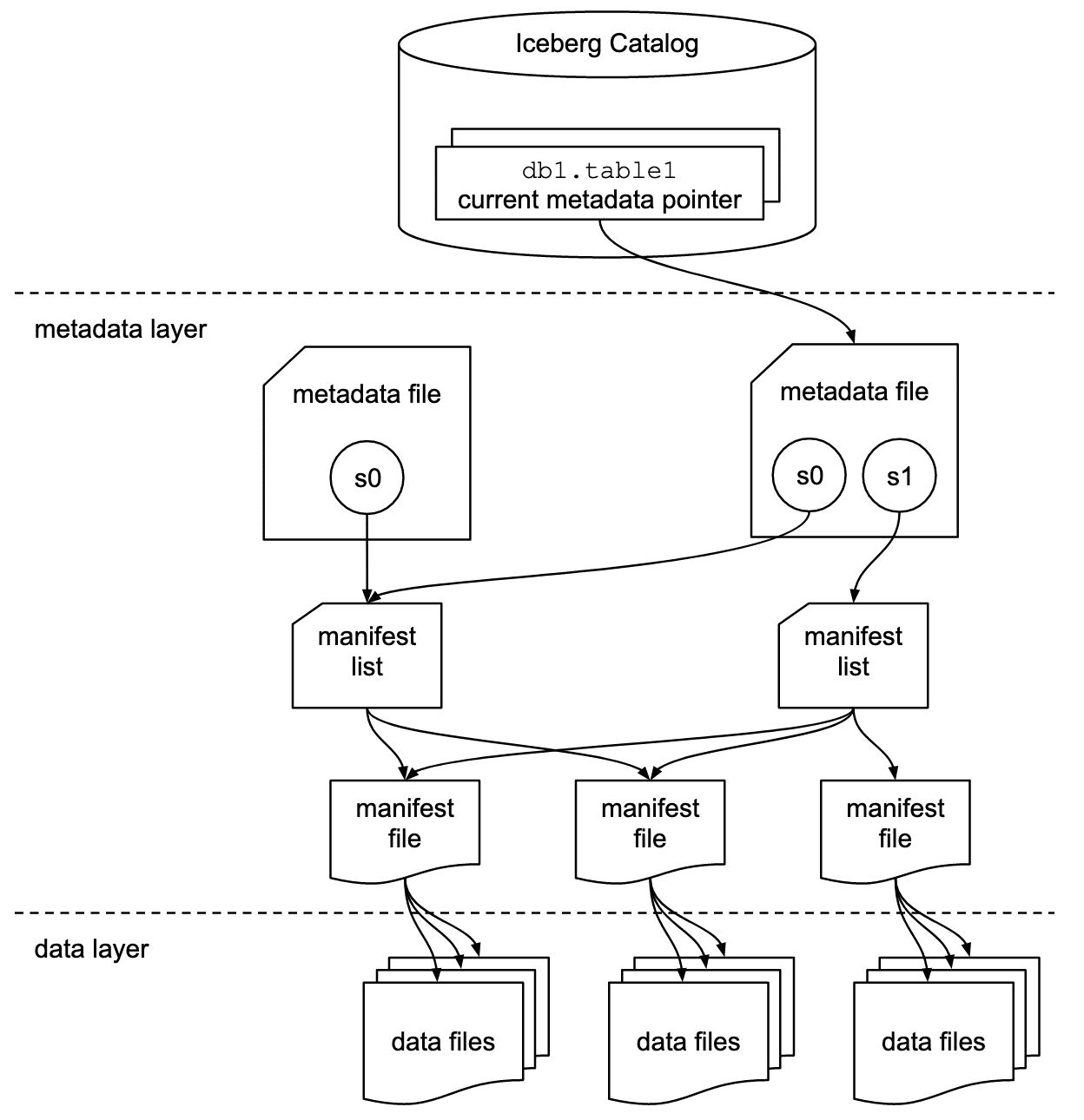
Iceberg Catalog
Iceberg Catalog - Iceberg catalogs can use any backend store like. In iceberg, the catalog serves as a crucial component for discovering and managing iceberg tables, as detailed in our overview here. An iceberg catalog is a type of external catalog that is supported by starrocks from v2.4 onwards. The catalog table apis accept a table identifier, which is fully classified table name. Clients use a standard rest api interface to communicate with the catalog and to create, update and delete tables. Iceberg uses apache spark's datasourcev2 api for data source and catalog implementations. In spark 3, tables use identifiers that include a catalog name. To use iceberg in spark, first configure spark catalogs. An iceberg catalog is a metastore used to manage and track changes to a collection of iceberg tables. Discover what an iceberg catalog is, its role, different types, challenges, and how to choose and configure the right catalog. The apache iceberg data catalog serves as the central repository for managing metadata related to iceberg tables. Discover what an iceberg catalog is, its role, different types, challenges, and how to choose and configure the right catalog. An iceberg catalog is a type of external catalog that is supported by starrocks from v2.4 onwards. Clients use a standard rest api interface to communicate with the catalog and to create, update and delete tables. They can be plugged into any iceberg runtime, and allow any processing engine that supports iceberg to load. Metadata tables, like history and snapshots, can use the iceberg table name as a namespace. Iceberg catalogs are flexible and can be implemented using almost any backend system. It helps track table names, schemas, and historical. Directly query data stored in iceberg without the need to manually create tables. Its primary function involves tracking and atomically. To use iceberg in spark, first configure spark catalogs. It helps track table names, schemas, and historical. Clients use a standard rest api interface to communicate with the catalog and to create, update and delete tables. They can be plugged into any iceberg runtime, and allow any processing engine that supports iceberg to load. Discover what an iceberg catalog is,. Metadata tables, like history and snapshots, can use the iceberg table name as a namespace. Iceberg catalogs are flexible and can be implemented using almost any backend system. Iceberg catalogs can use any backend store like. In iceberg, the catalog serves as a crucial component for discovering and managing iceberg tables, as detailed in our overview here. With iceberg catalogs,. With iceberg catalogs, you can: In spark 3, tables use identifiers that include a catalog name. In iceberg, the catalog serves as a crucial component for discovering and managing iceberg tables, as detailed in our overview here. An iceberg catalog is a metastore used to manage and track changes to a collection of iceberg tables. It helps track table names,. With iceberg catalogs, you can: Directly query data stored in iceberg without the need to manually create tables. Its primary function involves tracking and atomically. Iceberg uses apache spark's datasourcev2 api for data source and catalog implementations. Discover what an iceberg catalog is, its role, different types, challenges, and how to choose and configure the right catalog. Directly query data stored in iceberg without the need to manually create tables. The catalog table apis accept a table identifier, which is fully classified table name. Read on to learn more. Discover what an iceberg catalog is, its role, different types, challenges, and how to choose and configure the right catalog. An iceberg catalog is a metastore used to. They can be plugged into any iceberg runtime, and allow any processing engine that supports iceberg to load. With iceberg catalogs, you can: Discover what an iceberg catalog is, its role, different types, challenges, and how to choose and configure the right catalog. The catalog table apis accept a table identifier, which is fully classified table name. An iceberg catalog. In spark 3, tables use identifiers that include a catalog name. The apache iceberg data catalog serves as the central repository for managing metadata related to iceberg tables. The catalog table apis accept a table identifier, which is fully classified table name. They can be plugged into any iceberg runtime, and allow any processing engine that supports iceberg to load.. Iceberg catalogs can use any backend store like. An iceberg catalog is a type of external catalog that is supported by starrocks from v2.4 onwards. With iceberg catalogs, you can: Read on to learn more. They can be plugged into any iceberg runtime, and allow any processing engine that supports iceberg to load. The catalog table apis accept a table identifier, which is fully classified table name. Clients use a standard rest api interface to communicate with the catalog and to create, update and delete tables. In iceberg, the catalog serves as a crucial component for discovering and managing iceberg tables, as detailed in our overview here. The apache iceberg data catalog serves. To use iceberg in spark, first configure spark catalogs. It helps track table names, schemas, and historical. An iceberg catalog is a type of external catalog that is supported by starrocks from v2.4 onwards. Discover what an iceberg catalog is, its role, different types, challenges, and how to choose and configure the right catalog. They can be plugged into any. Iceberg uses apache spark's datasourcev2 api for data source and catalog implementations. An iceberg catalog is a type of external catalog that is supported by starrocks from v2.4 onwards. Read on to learn more. In spark 3, tables use identifiers that include a catalog name. Discover what an iceberg catalog is, its role, different types, challenges, and how to choose and configure the right catalog. Iceberg catalogs are flexible and can be implemented using almost any backend system. Iceberg brings the reliability and simplicity of sql tables to big data, while making it possible for engines like spark, trino, flink, presto, hive and impala to safely work with the same tables, at the same time. It helps track table names, schemas, and historical. Directly query data stored in iceberg without the need to manually create tables. An iceberg catalog is a metastore used to manage and track changes to a collection of iceberg tables. They can be plugged into any iceberg runtime, and allow any processing engine that supports iceberg to load. The catalog table apis accept a table identifier, which is fully classified table name. Iceberg catalogs can use any backend store like. Metadata tables, like history and snapshots, can use the iceberg table name as a namespace. To use iceberg in spark, first configure spark catalogs. The apache iceberg data catalog serves as the central repository for managing metadata related to iceberg tables.
Introducing the Apache Iceberg Catalog Migration Tool Dremio
Understanding the Polaris Iceberg Catalog and Its Architecture
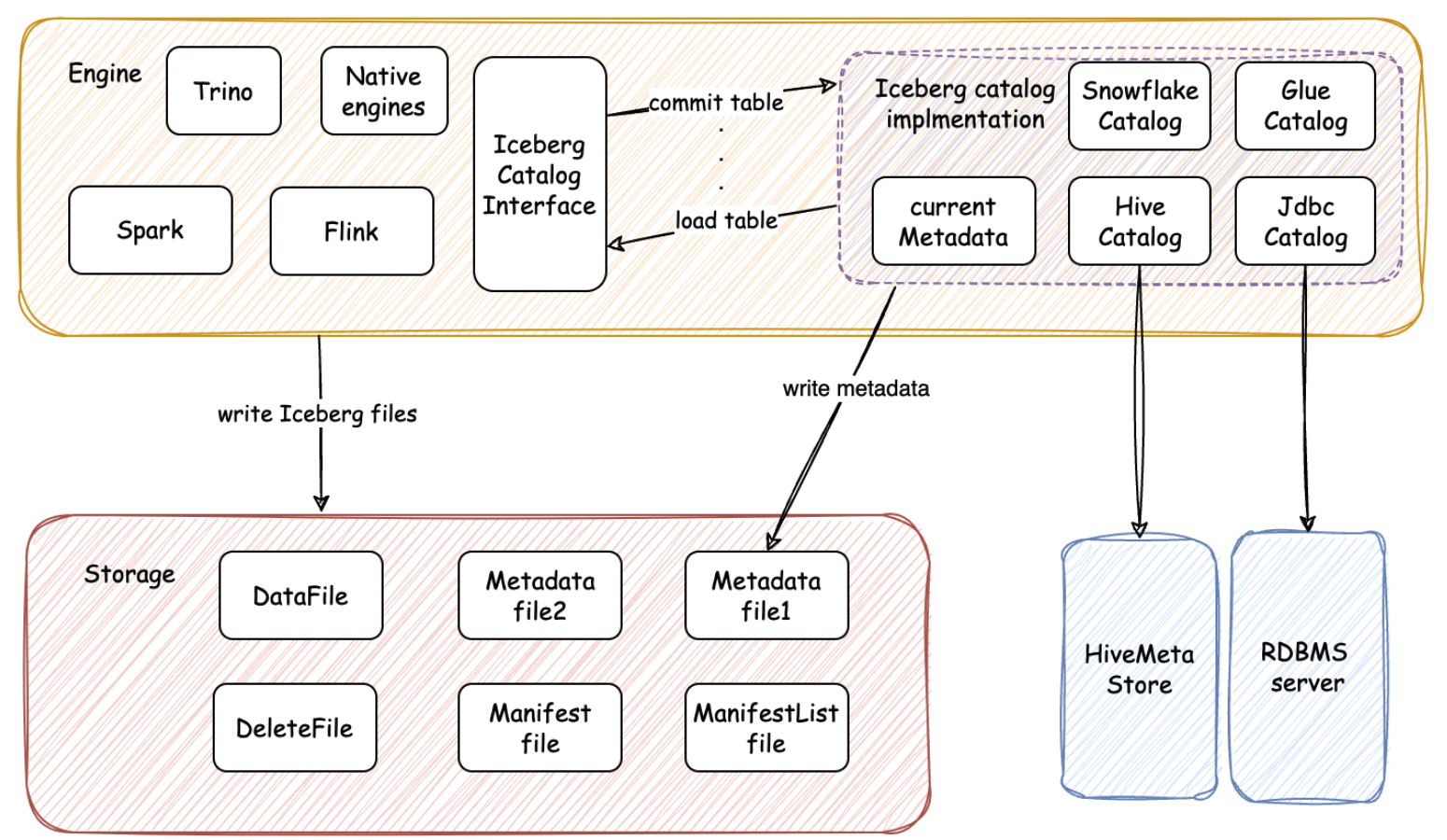
Gravitino NextGen REST Catalog for Iceberg, and Why You Need It
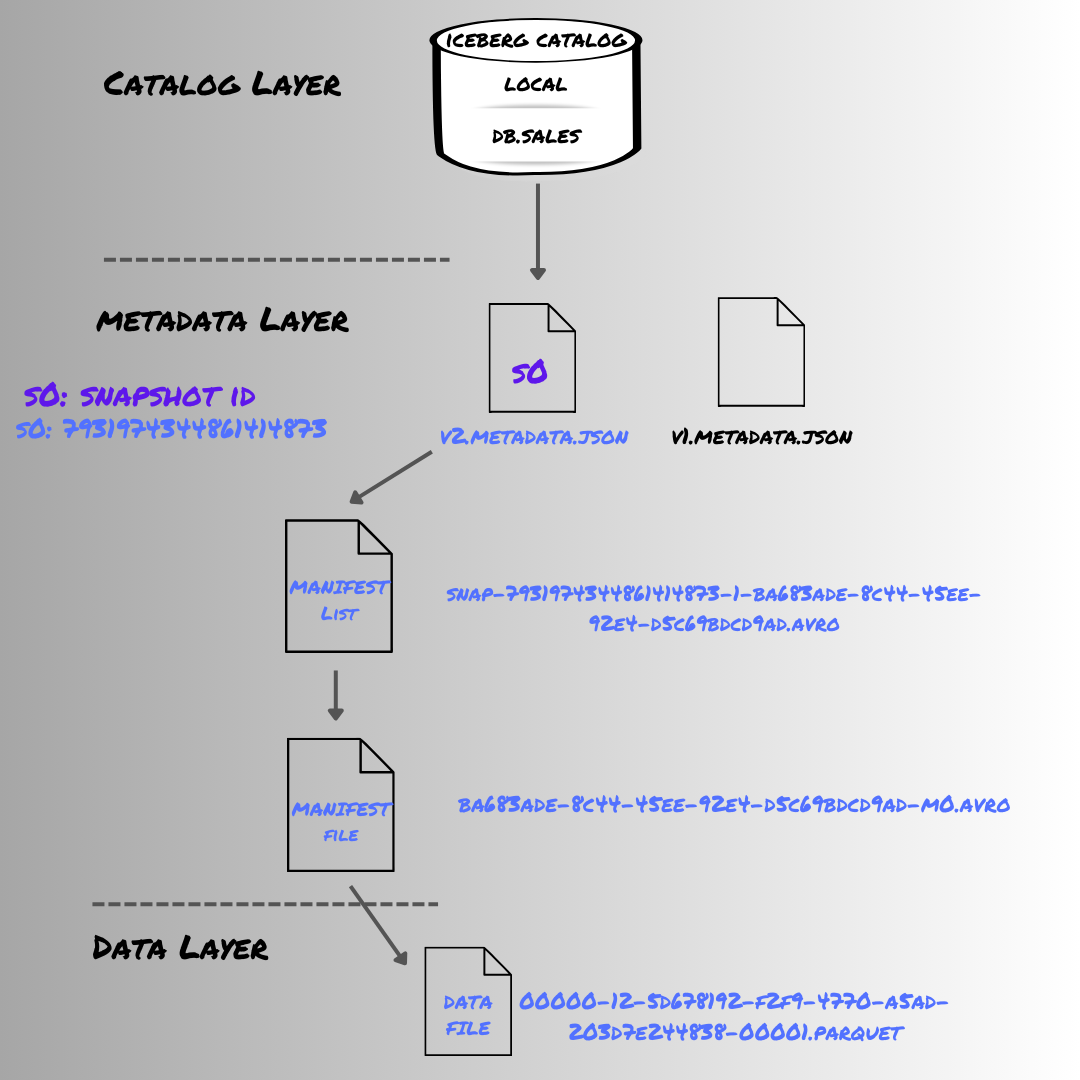
Apache Iceberg Architecture Demystified

Flink + Iceberg + 对象存储,构建数据湖方案
GitHub spancer/icebergrestcatalog Apache iceberg rest catalog, a
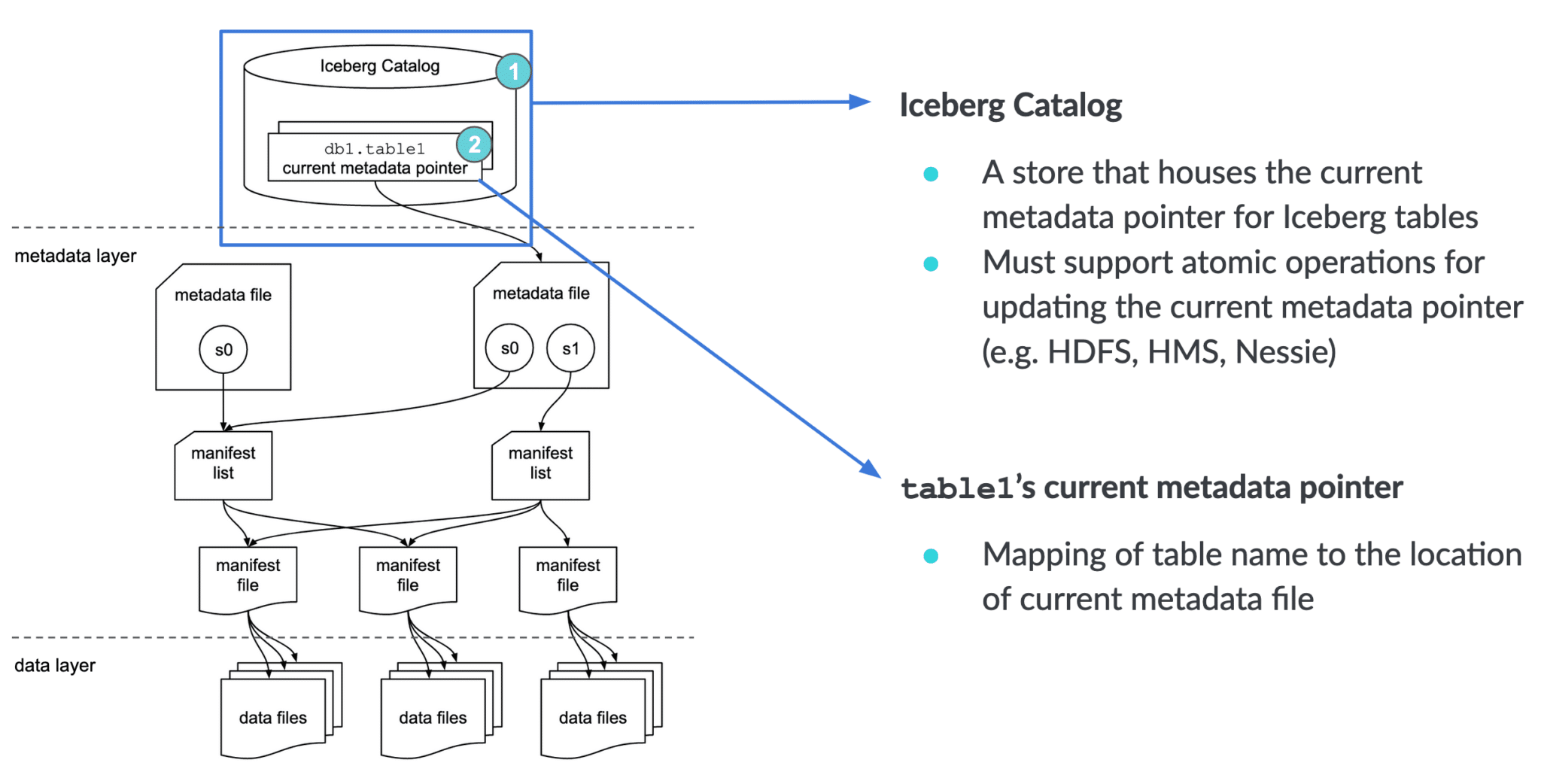
Apache Iceberg An Architectural Look Under the Covers

Introducing Polaris Catalog An Open Source Catalog for Apache Iceberg
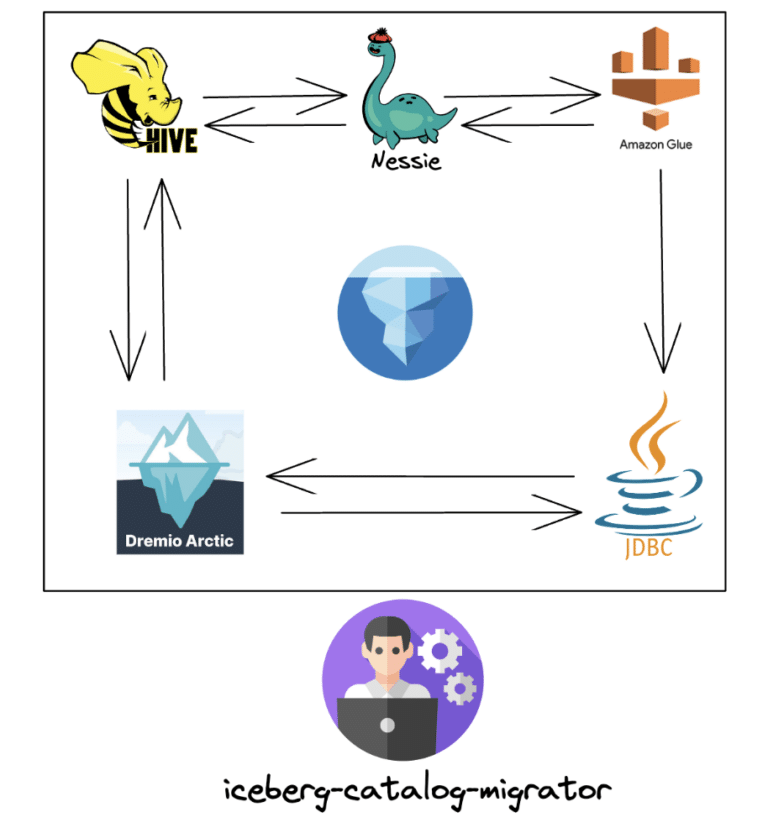
Introducing the Apache Iceberg Catalog Migration Tool Dremio
Apache Iceberg Frequently Asked Questions
In Iceberg, The Catalog Serves As A Crucial Component For Discovering And Managing Iceberg Tables, As Detailed In Our Overview Here.
With Iceberg Catalogs, You Can:
Its Primary Function Involves Tracking And Atomically.
Clients Use A Standard Rest Api Interface To Communicate With The Catalog And To Create, Update And Delete Tables.
Related Post:
